
Objetivo do trabalho
O trabalho busca desenvolver um dashboard que rode um modelo de machine learning capaz de prever o movimento do dia seguinte no indice ibovespa, baseado em dados históricos disponibilizados via API no yahoo finace, e para isso serão aplicadas técnicas estatisticas de regressão logística e regressão linear em series temporáis.
O resultado final esta disponível no dashboard que pode ser acessado em: Dashboard - URL
Aviso: Este estudo não é uma recomendação de compra ou venda, mas sim um estudo teorico de data science. O mercado financeiro é volátil e envolve riscos, por isso estude bem antes de realizar operações e converse com seu consultor.
Organização do trabalho
Premissas: Este trabalho foi realizado com a linguagem R, IDE Rstudio, e sistema operacional Linux Mint. Foram utilizados conhecimentos de data science e metodologias ágeis. Seguindo as boas práticas do mercado demos preferencia para bibliotecas do tidyverse.
Principais Etapas:
- Definição do objetivo do trabalho;
- Versionar trabalho no GitHub;
- Utilizar a ferramenta Kanban para organizar projeto no formato de metodologia ágil;
- Coleta dos dados;
- Realizar analise exploratória;
- Limpeza e tratamento dos dados;
- Salvar modelo treinado em arquivo r para posteriormente aplicar no framework tidymodels;
- Aplicar framework do tidymodels para desenvolver modelo;
- Avaliar resultados do modelo e necessidade de tunar os hiperparametros;
- Desenvolver um dashboard dinâmico com os pacotes flexdashboard, shiny e ploty;
- Realizar deploy do modelo and uploud in the shinyapp.io
Versionar trabalho no GitHub
Foi criado um repositorio para ajudar no armazentamento de arquivos e versionamento de todo o projeto. 
Kanban para organizar projeto no formato de metodologia ágil
Esta ferramenta serve para realizar gestão à vista do andamento de cada atividade ao longo do projeto. 
Coleta dos dados
Para construir uma primeira versão do modelo foram usados os dados históricos do índice Ibovespa futuro, filtrando o período de jan.2021 até jul.2022, disponíbilizados pelo site investing.com: 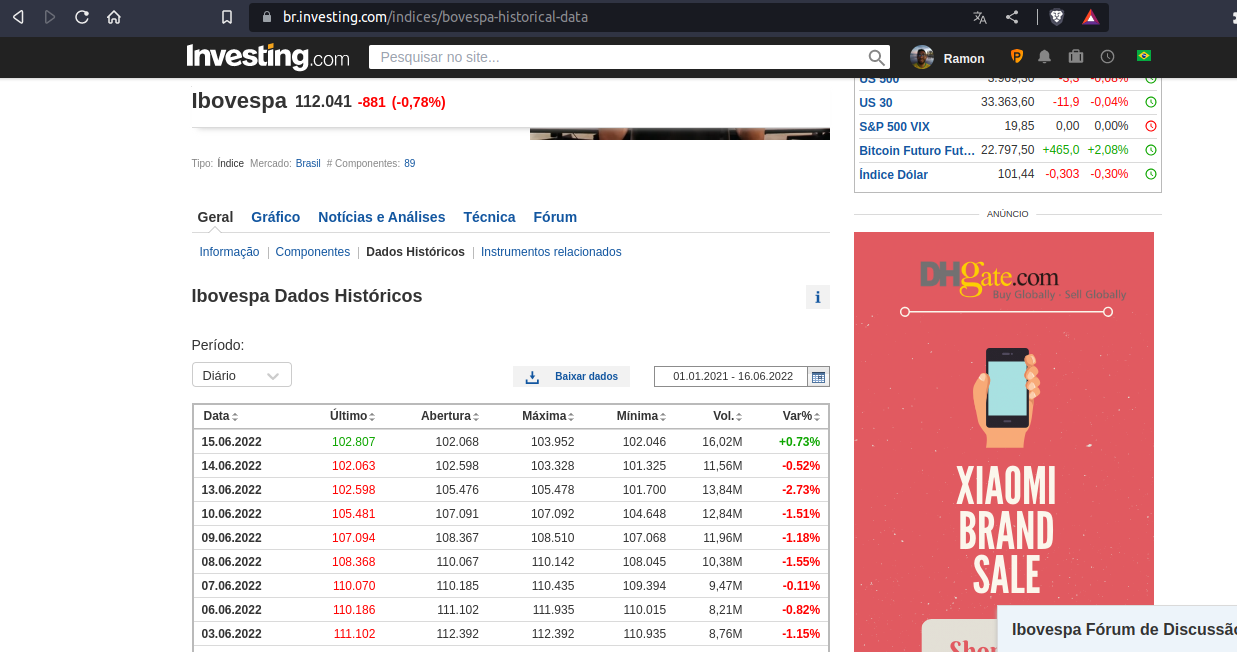
Analise exploratória
Começamos carregando o arquivo csv extraido do site investing.com para dentro do rstudio para entender melhor o formato dos dados disponibilizados:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
#Limpando Enviroment e Carregando principais Bibliotecas
rm(list = ls())
library(tidymodels)
library(readr)
library(janitor)
library(stringr)
library(lubridate)
library(ggplot2)
library(plotly)
library(DataExplorer)
#carregando Base extraida do site investing e adicionando uma coluna chamada meta
base <- readr::read_csv('Futuros Ibovespa - Dados Históricos.csv') %>% janitor::clean_names() %>%
dplyr::mutate(data = lubridate::dmy(data),
meta = dplyr::if_else(var_percent > 0,1,0) %>% forcats::as_factor()) %>%
dplyr::arrange(data)
#Avaliando tamanho da base e tipo primitivo dos dados
dplyr::glimpse(base)
Avaliando o dataframe notamos que as dimensões são 8 colunas e 361 linhas.
Trata-se de uma serie temporal com indexador de data mostrando as estatisticas do indice ibovespa ao longo de cada dia. Realizamos a tranformação da coluna data para um formato que utilizaremos, e também incluimos uma coluna chamada meta para entender o comportamento dos dados.
A ideia é que sempre que tivermos uma variação percentual positiva, coluna ultimo apresentar valor maior do que a coluna abertura, a meta tenha o valor um e caso contrario valor seja zero.
1
2
3
4
5
6
7
8
9
10
Rows: 361
Columns: 8
$ data <date> 2021-01-04, 2021-01-05, 2021-01-06, 2021-01-07, 2021-01-08, 2021-01-11, 2021-01-12, 2…
$ ultimo <dbl> 118.859, 119.393, 119.180, 122.684, 125.127, 123.120, 124.336, 121.959, 123.488, 120.3…
$ abertura <dbl> 120.320, 119.000, 119.195, 119.405, 123.050, 124.600, 123.805, 123.985, 122.775, 122.6…
$ maxima <dbl> 120.575, 119.955, 121.075, 123.450, 125.475, 124.910, 124.715, 124.385, 124.040, 122.7…
$ minima <dbl> 118.140, 116.770, 118.900, 119.235, 122.370, 122.465, 123.240, 121.015, 122.340, 120.0…
$ vol <chr> "162,34K", "179,66K", "182,04K", "176,66K", "190,05K", "164,15K", "113,43K", "237,23K"…
$ var_percent <chr> "-0,31%", "0,45%", "-0,18%", "2,94%", "1,99%", "-1,60%", "0,99%", "-1,91%", "1,25%", "…
$ meta <fct> 0, 1, 0, 1, 1, 0, 1, 0, 1, 0, 1, 0, 0, 0, 0, 0, 0, 1, 0, 1, 1, 1, 0, 1, 0, 0, 0, 1, 1,…```
Insigth: Avaliando a integridade dos dados para entender se por ventura temos algum valor ausente no dataset.
Design: Para construção desse gráfico utilizamos a biblioteca DataExplorer que possui gráficos especializados na analise exploratória e facilitam a analise.
1
2
#Avaliando tipos de dados e verificando dados faltantes
DataExplorer::plot_intro(base)
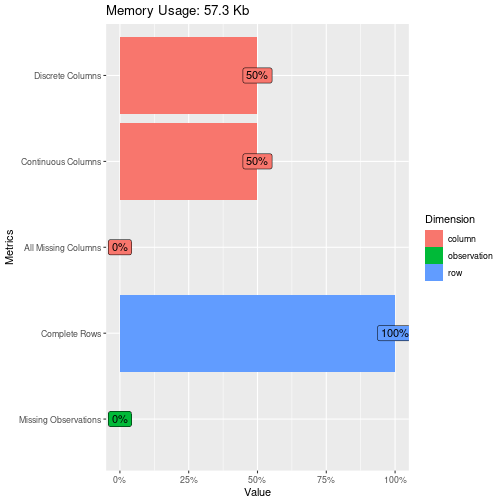
Como não encontramos dados ausentes seguimos para a próxima etapa que seria entender o comportamento dos dados ao longo do tempo. Insights: Analisando o gráfico notamos que o comportamento é variar dentro de um range de 100 a 140 pontos. Em alguns momentos essa oscilação é mais extrema do que em outros; Em alguns momentos existe certa tendencia mais evidente, e em outros notamos um comportamento aleatório.
Design: Para construção desse gráfico utilizamos os pacotes ggplot e ploty buscando uma solução elegante que armonize a qualidade visual quanto interatividade.
1
2
3
4
5
6
7
8
#Analisando gráfico da seríe temporal
ggplotly(
ggplot(base,aes(x = data,y = ultimo))+
geom_line()+
geom_point(color='blue',size=1)+
ggtitle('Gráfico Cotação Diária')+
scale_x_date(date_breaks = "1 month", date_labels = "%b %d")
)
1
2
## PhantomJS not found. You can install it with webshot::install_phantomjs(). If it is installed, please make sure the phantomjs executable can be found via the PATH variable.
## PhantomJS not found. You can install it with webshot::install_phantomjs(). If it is installed, please make sure the phantomjs executable can be found via the PATH variable.
1
## Error in path.expand(path): invalid 'path' argument
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
#Dividindo entre treino e teste
split_base <- initial_split(base,prop = .8)
train_base <- training(split_base)
test_base <- testing(split_base)
# Criando modelo ----------------------------------------------------------
lr_model <- logistic_reg() %>%
set_mode('classification') %>%
set_engine('glm')
# Criando Recipe ----------------------------------------------------------
lr_recipe <- recipe(meta ~ .,data = train_base) %>%
step_rm(var_percent,vol) %>% prep()
# Criando Workflow --------------------------------------------------------
wkf_model <- workflow() %>%
add_model(lr_model) %>%
add_recipe(lr_recipe)
# Treinando Modelo --------------------------------------------------------
lr_result <- last_fit(wkf_model,split = split_base)
# Avaliando Resultado -----------------------------------------------------
#Accuracy and roc_auc
lr_result %>% collect_metrics()
1
2
3
4
5
## # A tibble: 2 × 4
## .metric .estimator .estimate .config
## <chr> <chr> <dbl> <chr>
## 1 accuracy binary 0.822 Preprocesso…
## 2 roc_auc binary 0.915 Preprocesso…
1
2
#Matriz de Confusão
lr_result %>% unnest(.predictions) %>% conf_mat(truth = meta, estimate = .pred_class) %>% autoplot(type='heatmap')

1
2
3
# Salvando modelo Final ---------------------------------------------------
final_lr_result <- fit(wkf_model,base)
saveRDS(object = final_lr_result,file = 'win_model.rds')
Carregar Bibliotecas necessárias
1
2
3
knitr::opts_chunk$set(echo = TRUE)
library(flexdashboard)
library(shiny)
1
2
##
## Attaching package: 'shiny'
1
2
3
## The following object is masked from 'package:infer':
##
## observe
1
2
3
4
5
6
7
8
9
10
library(tidymodels)
library(readr)
library(janitor)
library(stringr)
library(lubridate)
library(ggplot2)
library(plotly)
library(patchwork)
library(knitr)
library(kableExtra)
1
2
##
## Attaching package: 'kableExtra'
1
2
3
## The following object is masked from 'package:dplyr':
##
## group_rows
1
library(quantmod)
1
## Loading required package: xts
1
## Loading required package: zoo
1
2
##
## Attaching package: 'zoo'
1
2
3
## The following objects are masked from 'package:base':
##
## as.Date, as.Date.numeric
1
2
##
## Attaching package: 'xts'
1
2
3
## The following objects are masked from 'package:dplyr':
##
## first, last
1
## Loading required package: TTR
1
2
##
## Attaching package: 'TTR'
1
2
3
## The following object is masked from 'package:dials':
##
## momentum
1
2
3
## Registered S3 method overwritten by 'quantmod':
## method from
## as.zoo.data.frame zoo
Carrega Modelo Salvo
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
Filtros {.sidebar}
--------------------------------------------------
#Carrega Modelo
modelo <- read_rds('win_model.rds')
#Carrega Base
base <- getSymbols(Symbols = '^BVSP')
base <- BVSP %>% data.frame() %>% rownames_to_column() %>% clean_names() %>%
rename("data"='rowname',"ultimo"='bvsp_close',"abertura"='bvsp_open', "maxima"='bvsp_high',"minima"='bvsp_low', 'vol'='bvsp_volume') %>%
mutate(data = as_date(data),
vol=as.character(vol),
var_percent= as.character(paste0(round(((ultimo/lag(ultimo))-1)*100,2),'%')),
meta = if_else(var_percent > 0,1,0) %>% as.factor(),
abertura= format(abertura,big.mark='.',decimal.mark=',') %>% as.numeric(),
maxima= format(maxima,big.mark='.',decimal.mark=',') %>% as.numeric(),
minima= format(minima,big.mark='.',decimal.mark=',') %>% as.numeric(),
ultimo= format(ultimo,big.mark='.',decimal.mark=',') %>% as.numeric(),
greenRed=ifelse(abertura-ultimo>0,"Red","Green")) %>%
select(-bvsp_adjusted) %>% filter(!is.na(ultimo))
shiny::dateRangeInput(inputId = 'periodo',label = 'Período',start = max(base$data)-60,end = max(base$data),language = 'pt')
#Botão para Download da série
downloadHandler(
filename = function() {
paste("dataset-", Sys.Date(), ".csv", sep="")
},
content = function(file) {
readr::write_csv(base %>% select(-c(var_percent,meta,greenRed)) %>%
filter(data>= input$periodo[1] & data <= input$periodo[2]), file)
})
#Filtra último dia do banco de dados
novo_dado <- base %>% filter(data == max(data))
#Aplica o modelo para obter a probabilidade de movimento do dia seguinte
resultado_valor <- round(if_else(predict(object = modelo, new_data = novo_dado)==0,
predict(object = modelo, new_data = novo_dado,type = 'prob') %>% pull(1),
predict(object = modelo, new_data = novo_dado,type = 'prob') %>% pull(2))*100, 2)
resultado_label=if_else(predict(object = modelo, new_data = novo_dado)==0,'Baixa','Alta')
1
2
3
## Error: <text>:1:9: unexpected '{'
## 1: Filtros {
## ^
Row {data-height=300}
Probabilidade e direção do Movimento
1
2
3
4
5
#Informa dentro do dashboard
renderGauge({
gauge(value = resultado_valor,label = resultado_label, min = 0, max = 100, symbol = '%', gaugeSectors(
success = c(80, 100), warning = c(40, 79), danger = c(0, 39)))
})
Concentração Dos Dados
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
renderPlot({
p1 <- ggplot(base %>% filter(data>= input$periodo[1] & data <= input$periodo[2]))+
geom_density(aes(x =ultimo),fill='blue',alpha=.25)+
geom_vline(xintercept = novo_dado %>% pull(ultimo) ,color='orange')+
ylab('')+xlab('')+
theme(axis.text.y = element_blank(),
axis.ticks.y = element_blank())
p2 <- ggplot(base %>% filter(data>= input$periodo[1] & data <= input$periodo[2]))+
geom_boxplot(aes(x =ultimo,y = 1),fill='blue',alpha=.25)+
geom_vline(xintercept = novo_dado %>% pull(ultimo) ,color='orange')+
ylab('')+xlab('')+
theme(axis.text.y = element_blank(),
axis.ticks.y = element_blank())
p1 / p2
})
Row {data-height=700}
Comportamento Histórico
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
renderPlotly({
ggplot(data = base %>% filter(data>= input$periodo[1] & data <= input$periodo[2]))+
geom_segment(aes(x = data,
xend=data,
y =abertura,
yend =ultimo,
colour=greenRed),
size=3)+
geom_segment(aes(x = data,
xend=data,
y =maxima,
yend =minima,
colour=greenRed))+
scale_color_manual(values=c("Forest Green","Red"))+
theme(legend.position ="none",
axis.title.y = element_blank(),
axis.title.x=element_blank(),
axis.text.x = element_text(angle = 90, vjust = 0.5, hjust=1),
plot.title= element_text(hjust=0.5))
})
Previsão com Regressão Linear
1
2
3
4
5
renderPlotly({
ggplot(data = base %>% filter(data>= input$periodo[1] & data <= input$periodo[2]))+
geom_smooth(aes(x =data, y = ultimo))+
ylab('')+xlab('')
})